Watch tutorial on Youtube.
More WordPress speed tutorials video playlist.
In this video tutorial I share how to protect WordPress and other big websites from crawling bots using the free Cloudflare Firewall.
Benefits of blocking with Cloudflare:
- No plugin solution.
- Crawlers blocked before reaching your web server.
- Expected huge reduction in bot traffic.
- Less server load.
- Protect website data from common bots.
Who is this tutorial for?
For big (more than 10k pages) website owners. It can be big blogs, forums, classifieds websites, game websites, business directories, big e-commerce websites etc.
I use it for gaming website with 40k games and multilingual classifieds website with more than 10k ads.
Which bots/crawlers should be blocked?
Bots that are not helping your website should be blocked in order to prevent waste of processing power of your web server.
Search engine bots should not be blocked because they send traffic to your website.
Block bots with following behaviours:
- AI training bots.
- SEO bots (meta title, description, content crawlers).
- Backlink crawlers.
- Web scrapers (email, phone, address collectors).
- User generated text and photo crawlers.
What are useless bots?
Useless bots use your website content plus processing prower and does not give anything back. They sell or use gathered data to their own advantage.
They do not care about win-win principle. You can win them by blocking their access to your website.
How crawler blocking works?
Every visitor to your website sends “User Agent” data to your server. User agent is provided by web browser or other software that requests web page from your website.
We add unique portion of User Agent string to Cloudflare custom Firewall rules. And instruct to block all requests containing this unique string.
Cloudflare checks every requests and blocks those that has matching “User agent” string. Not blocked requests can view your website without problem.
Instructions to block via “User Agent” in Cloudflare:
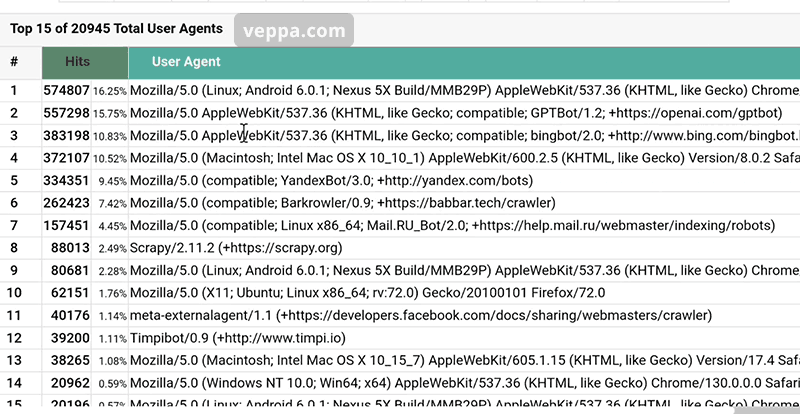
Step 1: Find top “User Agents” in webalizer report.
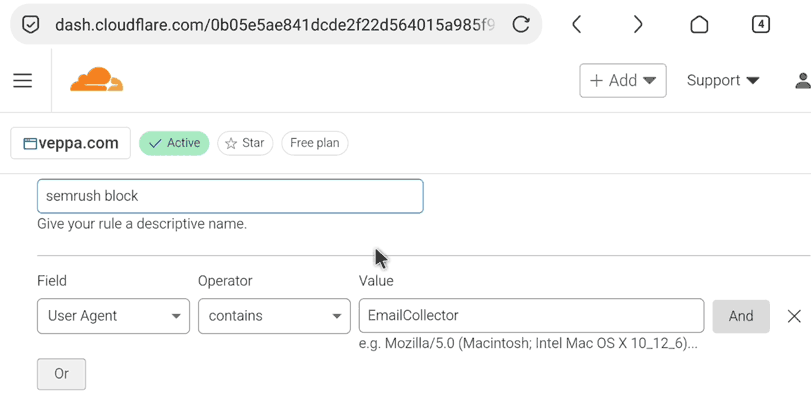
Step 2: Add custom WAF firewall rules with “Block” directive.
- Select domain in Cloudflare dashboard.
- Navigate to “Security” → “WAF” from menu.
- Click on “Custom Rules” tab.
- Click “Create Rule” button.
- Give descriptive name to the rule like “Useless bots”.
- Set following values to “Field”, “Operator” and “Value”. Use “OR” operator between each rule:
User Agent→contains→EmailCollectorUser Agent→contains→WebEMailExtrac- … add all useless user agents following similar structure.
- For “Then take action…” field select “Block” value.
- Click “Save” button at the bottom.
Step 3: Regularly (monthly, quarterly) detect and add new useless crawlers.
Copy/paste version of custom Cloudflare Firewall Rules with crawler “User Agent” strings as an expression.
This is not definitive list. Useless crawlers may be different for your website. Detect them for your own website using Webalizer report as explained in the video tutorial.
These are the current rules for my website. Paste it inside custom rules as an expression.
(http.user_agent contains "EmailCollector") or (http.user_agent contains "WebEMailExtrac") or (http.user_agent contains "TrackBack") or (http.user_agent contains "sogou") or (http.user_agent contains "SemrushBot") or (http.user_agent contains "AhrefsBot") or (http.user_agent contains "MauiBot") or (http.user_agent contains "DotBot") or (http.user_agent contains "BLEXBot") or (http.user_agent contains "MegaIndex") or (http.user_agent contains "MJ12bot") or (http.user_agent contains "NTENTbot") or (http.user_agent contains "TinEye") or (http.user_agent contains "GrapeshotCrawler") or (http.user_agent contains "istellabot") or (http.user_agent contains "alphaseobot") or (http.user_agent contains "Exabot") or (http.user_agent contains "Qwantify") or (http.user_agent contains "seekport") or (http.user_agent contains "linguee") or (http.user_agent contains "Avant") or (http.user_agent contains "MetaSr") or (http.user_agent contains "TencentTraveler") or (http.user_agent contains "360SE") or (http.user_agent contains "Maxthon") or (http.user_agent contains "World") or (http.user_agent contains "dataforseo") or (http.user_agent contains "petalbot") or (http.user_agent contains "babbar") or (http.user_agent contains "scrapy") or (http.user_agent contains "meta-externalagent") or (http.user_agent contains "timpi") or (http.user_agent contains "Amazonb")
FAQ
What are the other ways of preventing web crawlers?
There are 3 common ways to block web crawlers using “User Agent” string.
- Disallow with robots.txt directive. This instructs web crawlers to not crawl this website.
- Block using Nginx or Apache config rules.
- Block using Cloudflare Firewall rules. Cloudflare Proxy mode should be enabled for this to work.
Crawlers may ignore robots.txt instructions and still crawl your website. They cannot ignore (bypass) rules defined in web server (nginx, apache) or Cloudflare.
Is blocking via “User agent” scalable?
No, it is manual process. You regularly (monthly, quarterly) need to detect new crawlers and manually add them to blocking list.
Can web crawlers hide themselves and use browser “User agent” strings?
Yes, some bad bots/crawlers can hide themself by using common browser “User Agent” strings. They can use multiple IPs, multiple different user agents and still crawl your website entirely without being detected.
So blocking with “user agent” cannot protect from hidden crawler bots.
Why crawlers identify themselves with unique User Agent?
All reputable and official web crawlers provide identifiable “user agent” string in order to give you some control to block them. They are mostly obey robots.txt rules.
How to learn more about particular web crawler?
Some web crawler provide URL inside “User agent” string so you can learn more about that crawler. I used facebook crawler URL to learn more about it in the video.
You can also search for crawler in google using related “User Agent” string.
Conclusion
Blocking useless crawlers from accessing your website will reduce server load for websites with more than 10k pages. Blocking on cloudflare will prevent bots to reach your webs server. Detecting crawling bots and adding them to custom cloudflare rules is manual process.
Reputable crawlers always provide unique User Agent strings to give choice to website owners for blocking them.
What is next:
- Prevent WordPress spam using automated human validation with these custom rules in Cloudflare (without plugin).
- More WordPress optimization using Cloudflare.